A. 조인 분해를 통해서 성능상에서 이익을 얻는 경우가 많기 때문이다.
select_related와 prefetch_related SQL 쿼리 예
Q. 장고Django ORM에서 n+1 이슈란? n+1 이슈 해결 방법은?란 글에서 다뤘듯이 select_related는 INNER JOIN을 사용한다. prefetch_related는 INNER JOIN을 사용하지 않고 조인을 분해한다. 앞의 글에서 다뤘던 예를 다시 가져오면 아래와 같다.
select_related SQL 쿼리 예
SELECT `app_beverage`.id, `app_beverage`.name, `app_beverage`.category_id, `app_beverage`.price, `app_beverage`.is_available, `app_beverage`.created_at, `app_beverage`.updated_at, `app_category`.id, `app_category`.name, `app_category`.created_at, `app_category`.updated_at FROM app_beverage INNER JOIN app_category ON (`app_beverage`.category_id = `app_category`.id) LIMIT 4;
prefetch_related SQL 쿼리 예
SELECT `app_beverage`.id, `app_beverage`.name, `app_beverage`.category_id, `app_beverage`.price, `app_beverage`.is_available, `app_beverage`.created_at, `app_beverage`.updated_at FROM app_beverage LIMIT 4;
SELECT `app_category`.id, `app_category`.name, `app_category`.created_at, `app_category`.updated_at FROM app_category WHERE `app_category`.id IN (1);
prefetch_related는 INNER JOIN을 사용하지 않고 한 쿼리를 두 쿼리로 분해한 것으로 볼 수 있다.
select_related
INNER JOIN이 포함된 SQL 쿼리의 쿼리 코스트를 보면 1.5이다.

prefetch_related의 쿼리 코스트 합은 1.65다.
SELECT `app_beverage`.id, `app_beverage`.name, `app_beverage`.category_id, `app_beverage`.price, `app_beverage`.is_available, `app_beverage`.created_at, `app_beverage`.updated_at FROM app_beverage LIMIT 4;
의 쿼리 코스트는 0.65이다.

SELECT `app_category`.id, `app_category`.name, `app_category`.created_at, `app_category`.updated_at FROM app_category WHERE `app_category`.id IN (1);
의 쿼리 코스트는 1이다.

쿼리 코스트만 비교했을 때는 두 테이블을 풀 스캔함에도 INNER JOIN을 사용한 쿼리 코스트가 더 낮다.
왜 prefetch_related 사용하는 것을 권장할까?
1. 애플리케이션에서 캐시를 사용하는 경우가 많기 때문이다. prefetch_related를 사용해서 조인 분해해서 SQL 쿼리를 요청했다면 각 테이블별로 쿼리를 요청하게 된다. 이 경우 select_related를 사용해서 조인이 있는 쿼리보다 prefetch_related 테이블 별 쿼리가 중복 요청이 더 빈번하게 발생하게 된다. 따라서 이전에 요청한 것과 동일한 쿼리라면 캐시에 저장된 값을 사용하게 되어 데이터베이스에 질의 자체를 안 해도 되게 되므로 prefetch_related가 속도가 더 빠르다. 앞의 예에서 prefetch_related 쿼리 2개 중 1개는 이미 캐시에 저장된 것을 사용하고 1개만 질의하는 경우를 생각해 보면 쉽게 이해할 수 있다.
2. 한 데이터베이스 서버에서 읽기 쓰기를 모두 하지 않고 읽기 전용 복제(replication) 데이터베이스를 사용하는 경우가 많기 때문이다. 개별 쿼리의 쿼리 코스트를 본다면 조인 분해된 prefetch_related가 당연히 select_related보다 낮다. 당연히 개별 쿼리의 응답을 prefetch_related가 더 빨리 얻을 수 있다. prefetch_related가 더 성능상 효과를 거둘 수 있다.
3. 풀 테이블 스캔Full Table Scan을 줄일 수 있다. 위 예에서 볼 수 있듯이 조인 분해를 할 경우 IN() 리스트로 변경해서 조인하는 것을 볼 수 있다. 이 경우 인덱스 범위 스캔Index Range Scan이 이뤄진다. 데이터가 많다면 풀 테이블 스캔이 줄어드니 큰 성능 향상을 얻을 수 있다.
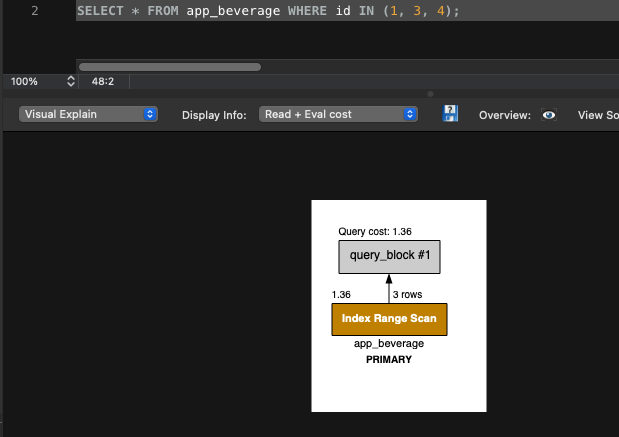
4. 데이터베이스 서버는 비싸다! 데이터베이스 부하를 줄이고 애플리케이션 서버의 부하를 늘리는 게 낫다. refetch_related는 SQL 쿼리는 조인 분해를 해서 데이터베이스 부하를 줄이고, 대신 장고가 조인하는 식이다. 장고에 부하가 늘지만 무조건 데이터베이스 부하를 줄이는 게 낫다.